Production-grade training for data engineering teams.
Hands-on Apache Kafka, Flink and Databricks training taught by a practitioner. Senior consulting in Web IDEs, DSL tooling, and cloud infrastructure.
Trusted by



Consulting
Areas of expertise
Data Platform Architecture
Real-time and batch data pipeline architecture using Kafka, Flink, Spark. Event-driven systems, OpenSearch indexing, stream processing at scale.
Web IDE Engineering
Architecture and integration of browser-based IDEs using Eclipse Theia and VSCode extension APIs. Custom plugins, on-premise deployment, white-label platforms.
DSL & Language Tooling
Design and implementation of domain-specific languages: grammars (ANTLR, Xtext), LSP servers, custom lexers/parsers, and code generation.
Cloud & DevOps Architecture
AWS infrastructure design (ECS, EKS), Terraform automation, CI/CD pipelines, Kubernetes deployments, observability (Datadog, ELK).
Training
Production-grade training for data engineering teams.
Hands-on Kafka and Flink training taught by a practitioner, not a generalist instructor. Every session is scoped to your stack, your team level, and your real use cases.
How it works
Scoping call
We meet before the training to understand your infrastructure, your team's level, and what you're actually trying to solve. No generic slides.
Custom preparation
Exercises, datasets, and examples are adapted to your context. Your team works on scenarios that look like their daily work.
Hands-on sessions
2 to 3 days on-site or remote. Theory is minimal. Most of the time is spent writing, running, and debugging real code.
Modules
Apache Kafka & Kafka Streams
Design and operate event-driven architectures in production.
This training covers Apache Kafka from the ground up to the real challenges of distributed systems in production: topic architecture, consumption strategies, stateful processing, schema management, and observability. Participants work on concrete use cases inspired by real-time systems deployed at Doctolib, GeoPost, and Nuant.
- ›Kafka architecture: topics, partitions, replication, consumer groups
- ›Producers, consumers, and advanced consumption strategies
- ›Kafka Streams: stateful processing, joins, windowing
- ›Schema Registry, Avro, and schema evolution
- ›Error handling, retries, and resilience patterns
- ›AWS deployment and monitoring with Datadog
Duration · 2 days
Level · Intermediate to senior engineers
Format · On-site or remote, 4 to 10 people
Stream Processing with Apache Flink
Build robust, fault-tolerant real-time pipelines.
An advanced training focused on distributed stream processing with Apache Flink: event time management, stateful operators, windowing strategies, and Kubernetes deployment. Content emphasizes real production challenges: fault tolerance, checkpointing, observability, and integration with modern data stacks.
- ›DataStream API and advanced transformations
- ›Event time, watermarks, and windowing strategies
- ›Stateful operators and distributed state management
- ›Checkpointing, recovery, and fault tolerance
- ›Deploying Flink on Kubernetes
- ›Integration with Kafka, OpenSearch, and PostgreSQL
Duration · 2 days
Level · Intermediate to senior engineers
Format · On-site or remote, 4 to 10 people
ML Engineering with Databricks
Industrialize data and machine learning pipelines on a lakehouse architecture.
This training covers Databricks as a production-grade data and ML engineering platform: data structuring, Spark optimization, collaborative notebooks, model deployment, and ML CI/CD. Examples and exercises are drawn from real data platform and ML industrialization projects.
- ›Unity Catalog, Delta Lake, and lakehouse architecture
- ›Spark DataFrames, GraphX, and performance optimization
- ›Collaborative development with Jupyter notebooks
- ›Model training, tracking, and versioning with MLflow
- ›ML pipeline CI/CD and deployment automation
- ›Production deployment on AWS and platform integration
Duration · 2 days
Level · Intermediate to senior data and ML engineers
Format · On-site or remote, 4 to 10 people
These training programs are built from real production experience on modern data stacks used at Doctolib, GeoPost, and Nuant. Beyond the fundamentals, they cover the architecture, observability, and scaling challenges encountered in the field.
Portfolio
Selected Work
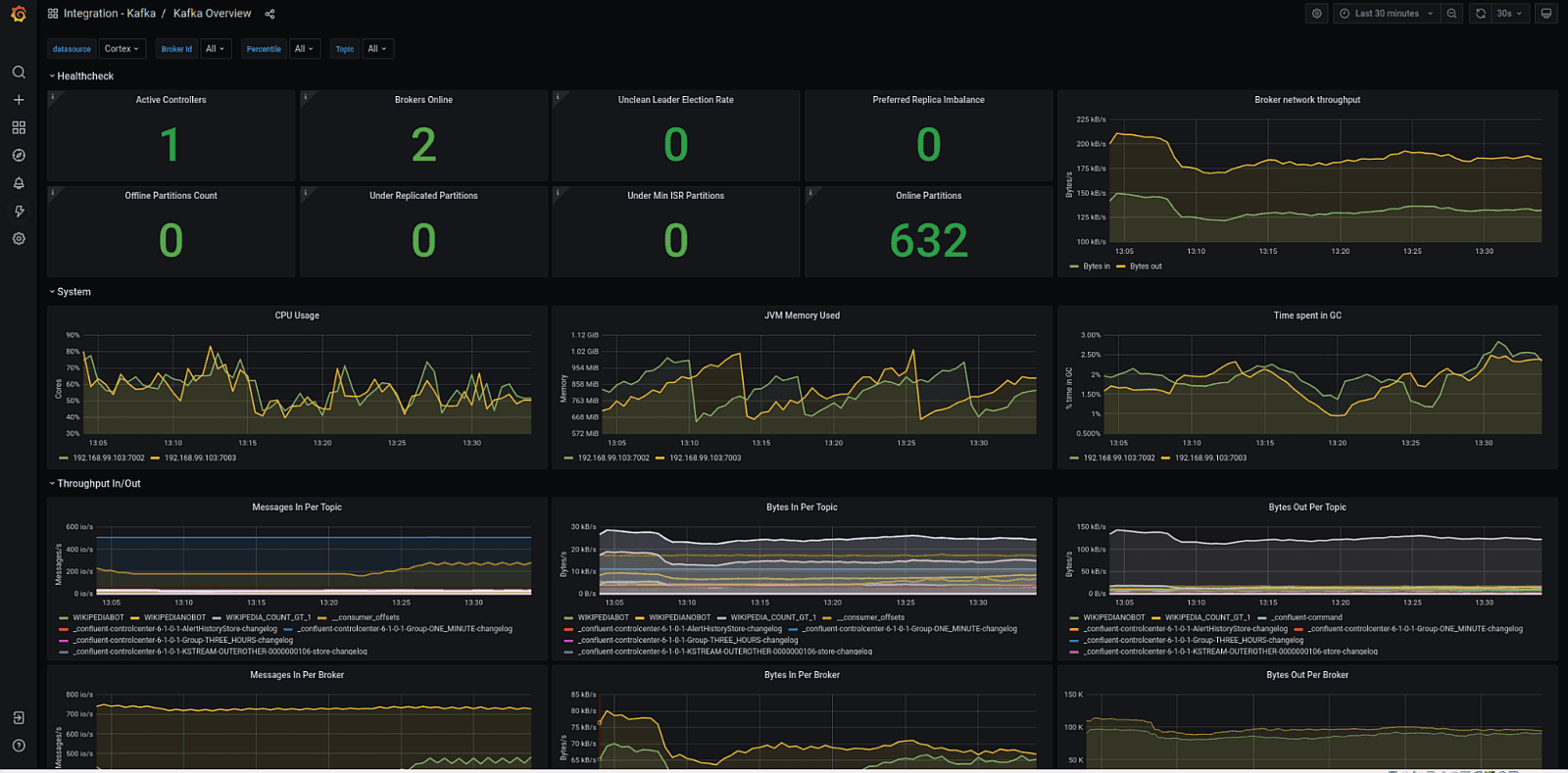
Doctolib
Data Architect
Brought a Kafka pipeline PoC to production in a highly constrained environment. Acted as the Kafka specialist and architecture challenger within a large engineering organization.
- ›Designed real-time + batch sync between the Doctolib monolith and OpenSearch via Kafka
- ›Challenged the existing architecture and proposed measurable observability improvements (Prometheus, Grafana, Datadog)
- ›Deployed on AWS EKS with full Terraform automation
- ›Coordinated integration with infrastructure teams across complex internal processes
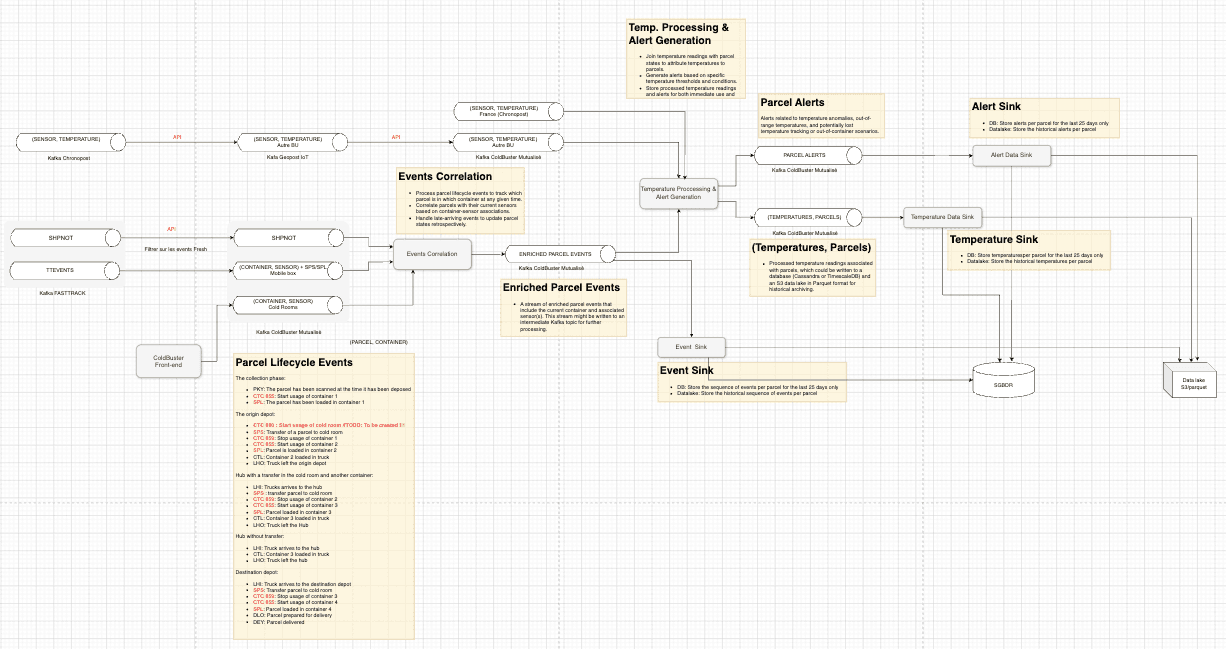
Geopost
Tech Lead / Data Engineer
Scoped and architected a real-time tracking solution for food parcel delivery from scratch: framed the business requirements, designed the data pipeline, defined the technical roadmap, and launched the first PoCs to put the project on solid rails.
- ›Scoped requirements and designed the full data pipeline architecture end-to-end
- ›Modeled and optimized a time-series database for high-frequency delivery events
- ›Built microservices for real-time event correlation and data persistence
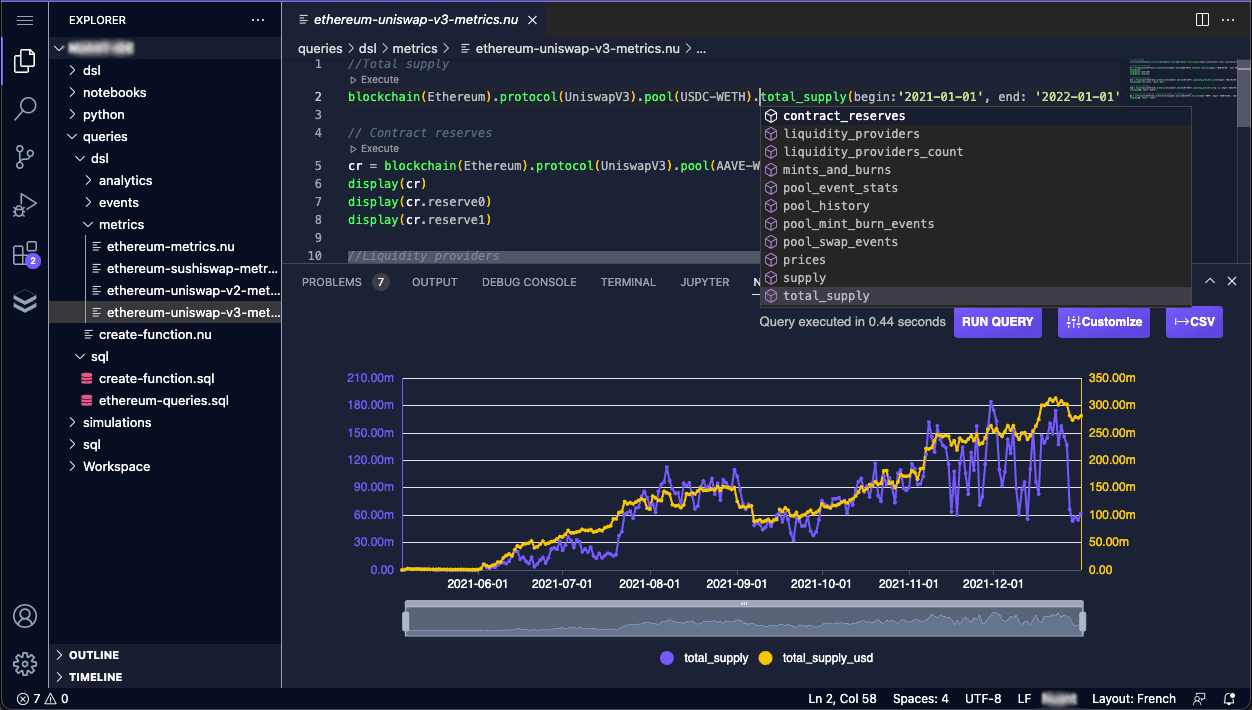
Nuant
Tech Lead / Data Engineer · Zurich
Near-CTO role in a demanding fintech / DeFi environment: coordinated multiple parallel projects across 10+ engineers, data scientists, infrastructure consultants, and external partners.
- ›Led the Web IDE project end-to-end: scoped requirements, delivered PoC, recruited and managed a 6-person team
- ›Industrialized a KYC blockchain transaction monitoring system from PoC to production API
- ›Developed Flink microservices for real-time computation of financial metrics from live asset price streams
- ›Designed a custom DSL for querying pre-computed blockchain metrics
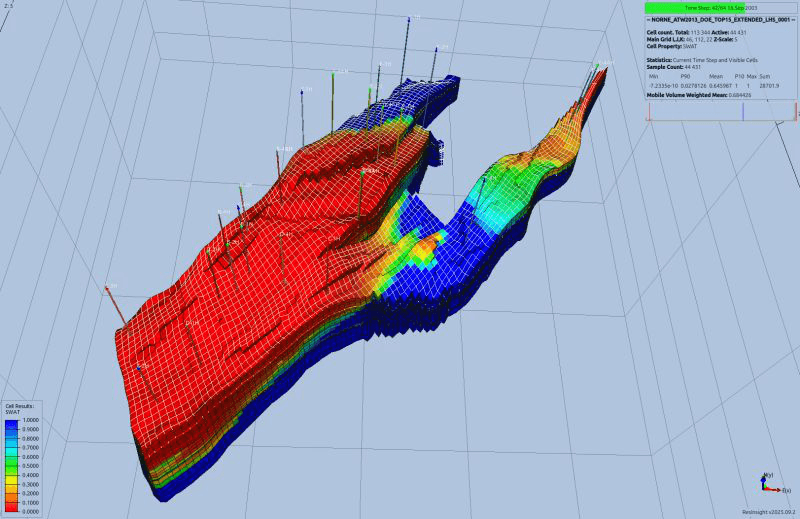
TotalEnergies
Software Architect
Modernized WISH, a well placement optimization component of the Sismage platform, a business-critical, scientifically complex codebase built on legacy CORBA middleware.
- ›Brought the component architecture into compliance with TotalEnergies standards
- ›Migrated part of legacy CORBA interfaces toward a modern REST architecture
- ›Developed a well visualization output module integrated into the Sismage UI framework
- ›Prototyped a web-based DSL editor for component configuration
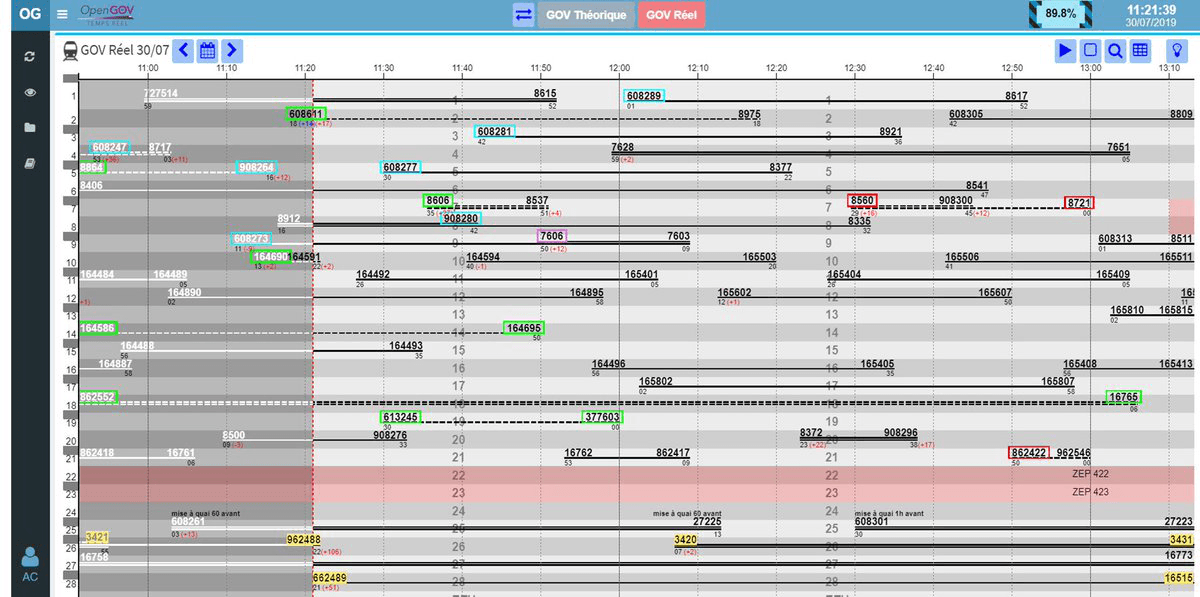
SNCF
Tech Lead / Software Architect
Rescued a web application for train station placement management left in critical state: fragmented codebase, no standards, multiple teams sharing the same repository with conflicting release cycles.
- ›Reframed project scope and established engineering standards from scratch
- ›Redesigned data model and refactored backend to separate concerns across teams
- ›Built CI/CD pipelines bringing the project from below PoC to production-grade quality
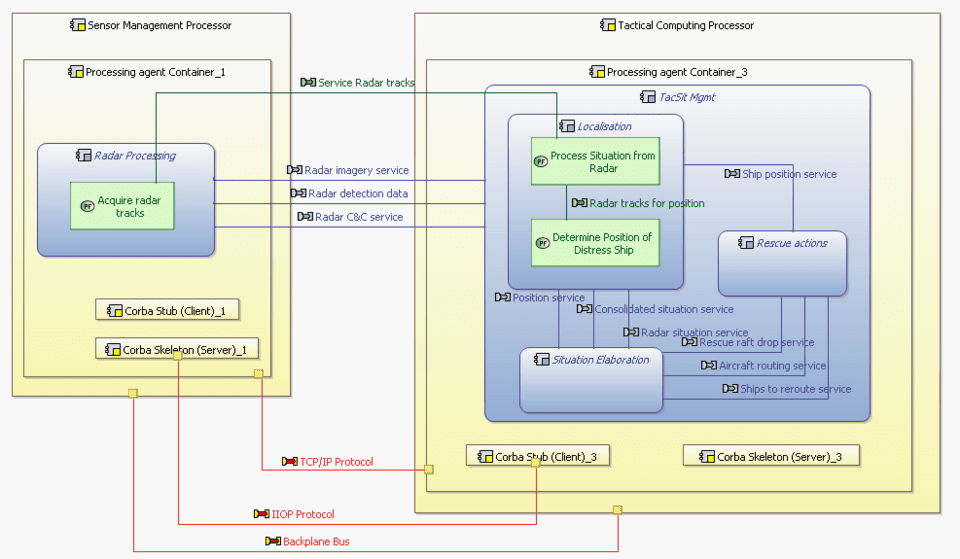
Thales
Software Architect
Several missions around MBSE tooling for systems engineers: design and implementation of domain-specific languages for architecture viewpoint specification and trade-off evaluation, integrated into the Eclipse Melody / Capella ecosystem.
- ›Designed and implemented DSLs for architecture viewpoint specification and evaluation
- ›Developed model co-evolution tooling for the Capella platform
- ›Contributed to multiple open-source projects under the Eclipse Foundation
Open Source
DSL Forge
80+ GitHub stars · Open-source framework
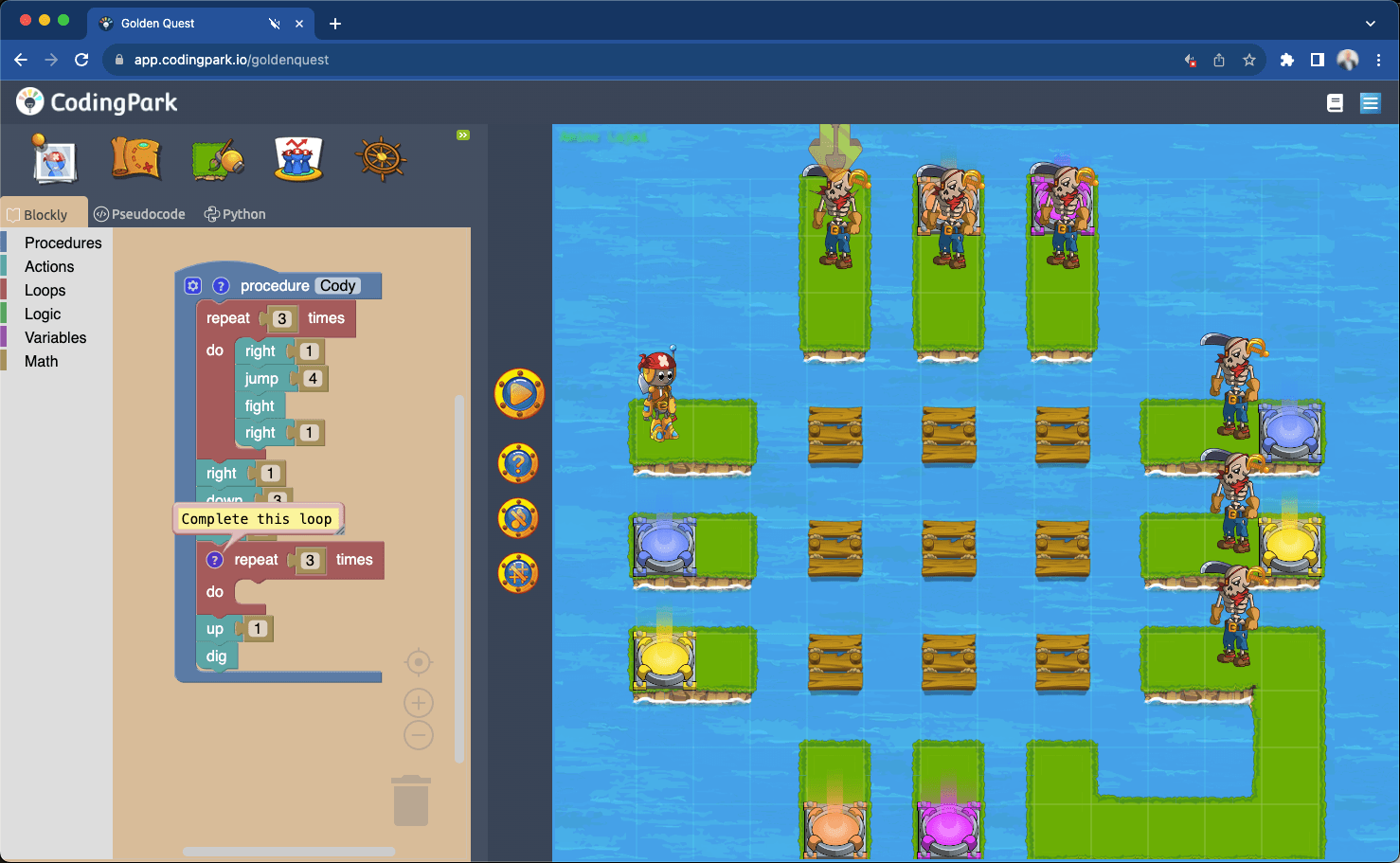
DSL Forge is an open-source framework for generating web-deployable textual DSL editors from ANTLR grammars. It bridges the gap between language specification and browser-based IDE tooling, powering both Coding Park's interactive coding environment and client DSL platforms.
Developed during the Continental mission (2012–2014), open-sourced and maintained since. Used as the technical foundation of Coding Park (educational platform for primary schools). Funded in part by CIR/CII declarations under JEI status.
About
About Plugbee

Amine L.
Amine Lajmi — PhD in Computer Science · Founder & Senior Engineer
Founded in 2015 by a computer science PhD, Plugbee works at the deep end of the developer tools stack: Web IDEs, language servers, DSL runtimes, and cloud infrastructure. An ecosystem where very few consultants operate at a senior level.
The company was born out of 10+ years of hands-on architecture work across 8 industries: aerospace, finance, energy, logistics, transport, and education. Every engagement has been at the architecture or tech lead level. No generalist work, no junior handoffs.
Plugbee also maintains DSL Forge, an open-source framework for generating web-deployable DSL editors, and was the technical backbone behind Coding Park, an interactive coding platform for primary and secondary school students.
Contact
Let's work together
Available for training engagements and senior consulting in Web IDEs, DSL tooling, and data platform design.
Based in Paris, France · Remote-friendly